(This is part 2 of a series – please read part 1 first)
How does one go about choosing data for a machine learning problem? What does it even mean to choose data? In this article we will discuss data types, what data to choose and why you should not (paradoxically!) choose anything!
If you have not read the previous blog in this series and you are new to the concepts of data science and machine learning, please read that first as it provides an introduction to key concepts we will use in this article.
Let us begin with a hypothetical example that is small enough and relates well enough to our everyday human knowledge and experience that it can serve as a learning aide.
The problem we will model is to determine what correlation (a connection between two or more things) exists between people’s height and their weight. We have an instinctive feeling for what this relationship is, that the taller a person is, the more likely they are to weigh more. And we also know that this is not always true. We can see the problem in our mind’s eye and we can see the challenges our assumptions make.
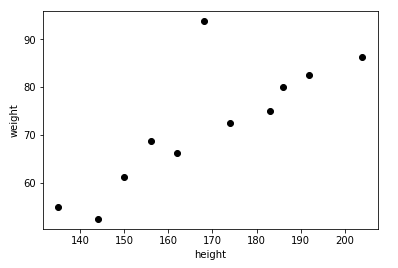
The example above is a simple linear regression model. When we collect data on the heights and weights of people we can create a scatter graph like the first one below. The numbers at the bottom are the X axis and in this case represent people’s heights. The numbers up the left hand side are the Y axis and in this case represent people’s weight.
We can see that taller people in general weigh more than shorter people, but this does not always hold true. We can see one person who weighs around 100kgs and has a height of 170cm. This is called an outlier.
If we now fit a linear regression line to the data, we will get the following graph.

The linear regression line tells us what the expected value is for every combination of height and weight. So given a certain height, we can predict the weight of the person. As we can see from the graph this is not an exact science – in fact only three points are actually on the line. The distance between a point and where it should intercept (touch) the line is called the error. Clearly our error for the outlier is very large, while most other data points have a lower error.
A very simple form of machine learning would calculate the line that best fits the available data. The best fit line would minimize the total sum of all the errors. While this may sound complicated it is a fairly easy exercise. All we need to do (in essence and skipping the math and statistics) is measure how far each data point is from the line and then add up all these errors. For the curious a common way to do this is called Mean Squared Error.
Why do we have an outlier in the graph above, and what can we do to eliminate these or use them to improve our predictive capability? This is where machine learning triumphs! We can add additional features to our data sets and use these additional features to improve our prediction. Unfortunately, when we do this, we need to say good-bye to the graphs above and start using our imaginations. We will need to add (many) additional dimensions to our dataset. We can create a 3D graph using visual tricks, but we cannot produce 4D graphs or graphs with much higher dimensions.
Let us begin by taking a walk through an imaginary city – we will pick a cosmopolitan city made up of a diverse range of cultures, ages, occupations and interests. We can choose New York or London, or any other large vibrant city. What would you expect in this city? You will find health enthusiasts, comic book aficionados, vegans, fast food addicts, doctors, lawyers, personal trainers. You will have Americans, Swiss, Chinese. You will of course have males and females and transgenders. And you would expect each of these people to have a certain height (mostly as a result of genetics) and a certain weight (a combination of genetics and lifestyle). Which of these characteristics (features) are important in determining height/weight correlation? Spend some time in this imaginary place and see what you can determine. This is an important exercise and will assist you in future data selection processes.
In your exploration of the city above did you make generalisations? Did you expect certain nationalities to be heavier on average? Did you perhaps expect a personal trainer to be fitter and leaner than an office worker? What effect on weight did you attribute to diet? With your vast (but fallible!) knowledge of humans acquired over decades of life you will have reached certain conclusions. If you expected an office worked to weigh more than a professional athlete you may well be incorrect if the office worker runs ultra-marathons as a hobby. However, you may be thinking, how was I to know she runs ultra-marathons? That information was not made available to me! This is the same problem machine learning has – it can only use features that you have provided to it. And it may not always be obvious up-front what affect certain features will have on predictive capabilities.
The advantage of machine learning is that we need not determine the features to use. In fact, we should not! We should not predetermine what features are important as this limits the machine from learning novel relationships. We simply add everything we have to the model and allow it to find the relationships and dependencies for us! And machines do not have any issue with multi-dimensional analysis (other than computing power and memory). We can (and should) at a later stage remove some features – but we can investigate that in a later article.
(Some readers may wonder about the effects of multicollinearity etc but we can tackle that at a later stage)
The more features we have the more we can mitigate the risks of an algorithm suffering from incorrect (or limited) predictive ability owing to missing features. As we provide additional features to a model, so it should improve its predictive capabilities. Since a machine learning algorithm is mathematically derived it does not make errors in prediction – it makes the correct predictions based on the information it has. It is the underlying data sets that may be insufficient to the task at hand.
One final point that needs mentioning is the importance of sample size. Sample size is the number of data points in the model. In our imaginary city it is the number of people we can see, and for whom we have detailed information. If we only have one person from Iceland and she is a data scientist that enjoys reading Shakespeare on the weekends, it would tell us very little about Icelanders, data scientists or people who enjoy Shakespeare. There simply is not enough information to determine if she is the norm or an outlier. The more examples of “data scientists” we have, the more we can predict about the weight of a data scientist of a certain height. And similarly for Icelanders and Shakespeare enthusiasts. Our datasets need to contain a representative set of samples for as many subjects as we can.
In conclusion, machine learning algorithms require as much data, with as many features, as possible to learn the best predictive models. It may not always be obvious what data will be useful and what data will not. What we need to know is what problem needs to be solved and what datasets we have available to us (or can acquire through credible external data partners). We can then allow the machine to learn the best fit for the problem area and provide us with predictions.
